Programmatically scrape using python
Why use python Useful python packages for webscraping
Python for webscraping
Python is well suited to programatically scrape data from websites. There are three major packages used to webscraping in python.
Beautifulsoup is used for extracting and parsing (breaking down) static web content
selenium is used to navigate webpages, input data into text fields, take screenshots and interact with dymanic web content
scrapy is a framework for webscraping, look into it once you become comfortable with coding. We will not work with scrapy in the workshop, however, this workshop offers a nice overview.
Static web content is built into the webpage, that is, its does not store any extra data on a remote server (think of a wikipedia page).
In contrast, dynamic content is stored on a remote server and when you interact with the page it sends or posts data from a remote server. Think of facebook, you can write comments in a post which and watch videos. Dynamic content is often hidden on a remote server and will not be visible to a webscraper without first interacting with the webpage so that the server posts it.
Beautiful Soup
Beautiful soup is useful for scraping static content of a website, this includes the html content. To get started we need to import requests, this package will return a http response from the page we are interested in scraping. We will also import BeautifulSoup from the bs4 package. This is used for getting the web data.
# import all required packages
import requests # get and post data to anf from websites
from bs4 import BeautifulSoup # get html from a website
import selenium # interacting with a website
import pandas as pd # good for working with dataframes
#pip install wordcloud # run this line once to install the wordcloud package
from wordcloud import WordCloud # create wordclouds
import matplotlib.pyplot as plt # used to plot the wordcloud
import math
# Supply the URL that you would like to scrape
quotes_url = 'https://quotes.toscrape.com/'
# Pull (download) all html data from the URL supplied above
html_text = requests.get(quotes_url).text
#Parse the pull html data - make it look pretty
quotes_soup = BeautifulSoup(html_text, 'html.parser')
#Print out the html data that was just pulled. It is identical to the websites html code.
print(quotes_soup)
First we created a variable called quotes_url, this is the url or webpage that you want to scrape. Then we pass it to the requests function get, which gets a response from the webpage and returns all the html text back as a single chunk. You can see the output of this by running “print(html_text)” in your python console. Now we can use beautiful soup to parse this into something that is readable, in this case html content. Run “print(quotes_soup)”. This is now the same html as is visible when we use a browser to inspect the webpage. You can copy this text, save it as .html and then open it using your web browser. It will only contain the text, the links will not work. This is because we have only scraped the data from the main page, we have not scraped any of the data from the links. Also, it will not look pretty, again, this is because we have not collected the website code that dictates its style.
Now that we have scraped all the text from the main page of quotes to scrape, we should collect the specific information that we are after.
Collecting specific information can be easy if there are html tags for it. For example, we can extract quotes using their tag.
Lets inspect a quote using our browser. The following image shows that the quotes sit within the body, then under the span tag.
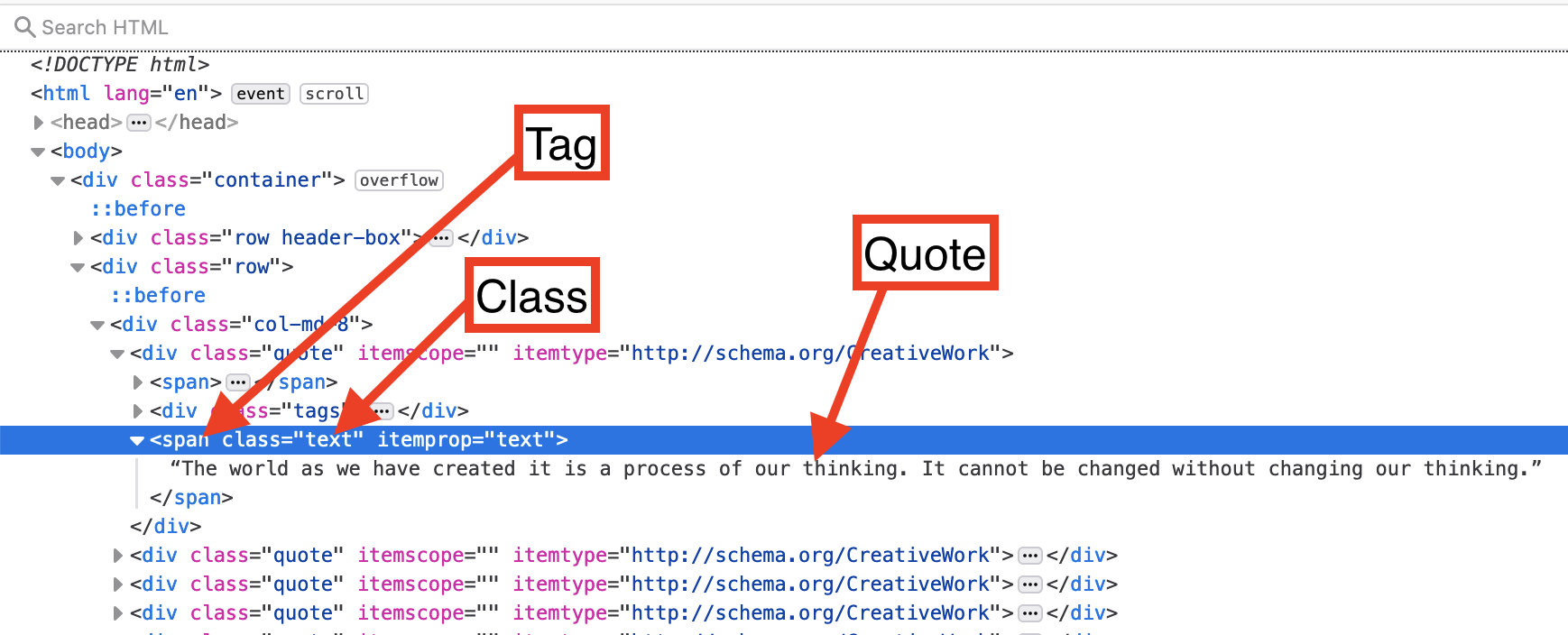
We can use the tag and class to access quotes. This will get the first quote.
# Use the find_all function to pull just the html for each quote
quote = quotes_soup.find_all('span', class_='text')
print(quote)
# Notice that the html information is still attached to each quote. i.e. the span tag <span></span>
# and the class and itemprop attributes
This has returned us a list with all the quotes on the first page. We still have some html code that we are probably not interested in. We can access the text of an individual quote using the .text command. We will subset our quote list to the first element and return the text. Remember [] are used to subset a list, and 0 will return the first element in the list quote.
# We can remove the html information with .item. Remeber that [] are used to access different elements in a list.
# quote[0].text will return the text portion of the first element from the variable quote
print(quote[0].text)
Lets retrieve the text only for the quotes. We will use a loop to go through the list. We will add the quote text to a new list called quotes.
# The easiest way remove the html from all quotes is with a for loop
quotes = [] # create a new empty list to append the text to at the end of each loop iteration
for i in quote:
quotes.append(i.text) #append will add each iteration to the list quotes
print(quotes)
#Now we have just the quotes
That looks good.
Challenge
Use your web browser to inspect the authors and figure out how you can get their names.
Solution
Lets you our web browser to inspect author.
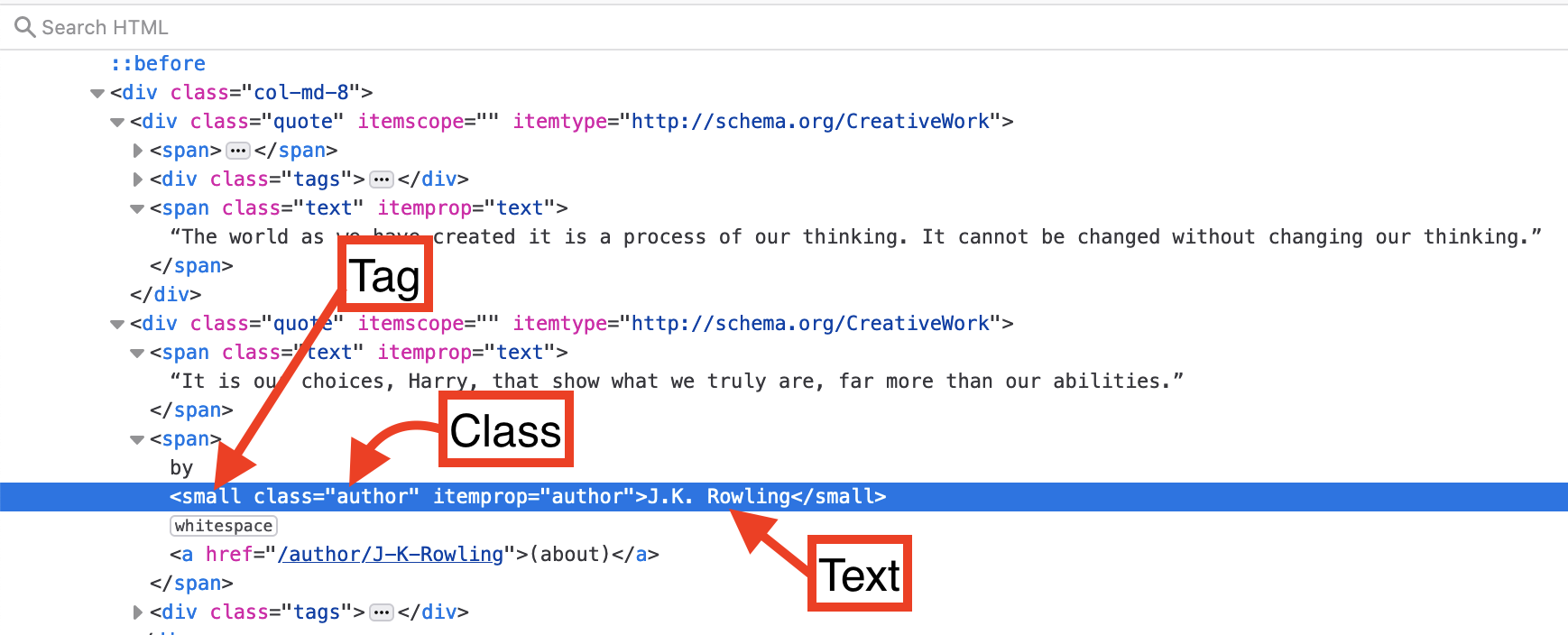
```python author = quotes_soup.find_all('small', class_='author') authors = [] for i in author: authors.append(i.text) print(authors) ```
Now we need to scrape the quotes from all of the pages. First we need to figure out how to move to the next page, use your browser to inspect the next page button.
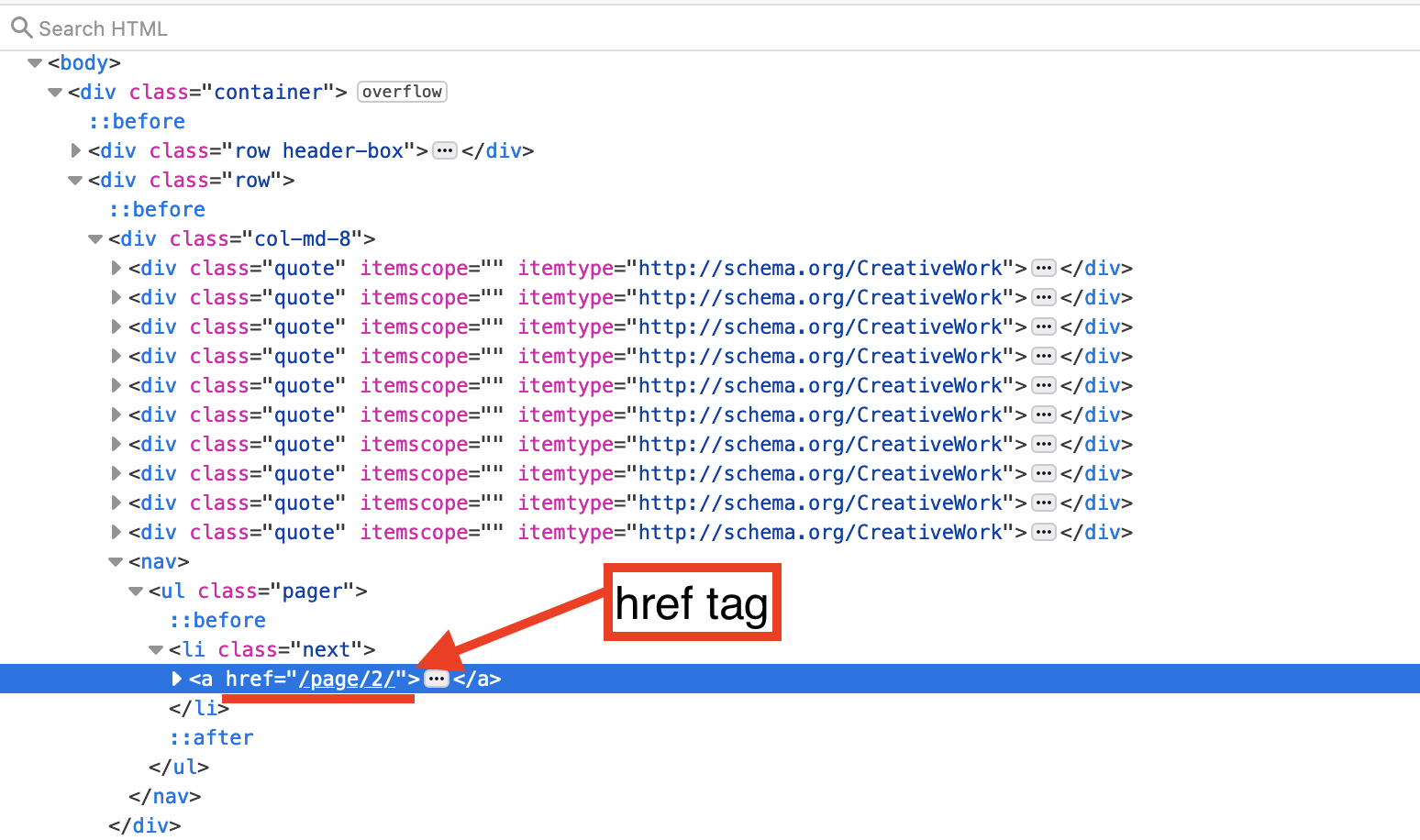
It contain a href tag. This is a url, although it does not include the base url: https://quotes.toscrape.com. We can use this url to move to the next page, then we can scrape data from it. If we start at 1 page, scrape data, move to page 2 scrape data, ect, until we finish at the last page then we will have scraped all pages. So…… how do we do this?
First we need to create a list that contains the url’s for all the pages. i.e. [“https://quotes.toscrape.com/page/1/”,”https://quotes.toscrape.com/page/2/”,”https://quotes.toscrape.com/page/3/”] Second, we can use the list of url’s to loop through each page and collect its html content and add it to a list. i.e. [“html content page 1”,”html content page 2”,”html content page 3”] Finally we can extract the individual quotes and authors from the list of html content.
pages = []
for i in range(0,20):
page = "https://quotes.toscrape.com" + '/page/' + str(i) + '/' # create a string of the url, with each loop the page number increases by one
pages.append(page) # write each url to a string
print(pages)
# lets create a list containing all the html content for each author and each quote
quote_soup = []
author_soup = []
for i in range(1,len(pages)):
quotes_url = pages[i]
html_text = requests.get(quotes_url).text
quotes_soup = BeautifulSoup(html_text, 'html.parser')
quote = quotes_soup.find_all('span', class_='text')
author = quotes_soup.find_all('small', class_='author')
quote_soup = quote_soup + quote
author_soup = author_soup + author
print(author)
authors = []
quotes = []
for i in range(1,len(author_soup)):
authors.append(author_soup[i].text)
quotes.append(quote_soup[i].text)
print(authors)
Lets create a wordcloud of all the quotes we scraped, because, well, science is also pretty!!!
quotes=" ".join(map(str,quotes)) # turns the list of quotes into a single string of all quotes i.e. ['a', 'b', 'c'] -> 'a b c'
print(quotes)
wordcloud = WordCloud().generate(quotes)
# Display the wordcloud image
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()

Often we’re interested in scraping data that is associated with specific tags, such as a Twitter #tag. Lets scape quotes based on their tags.
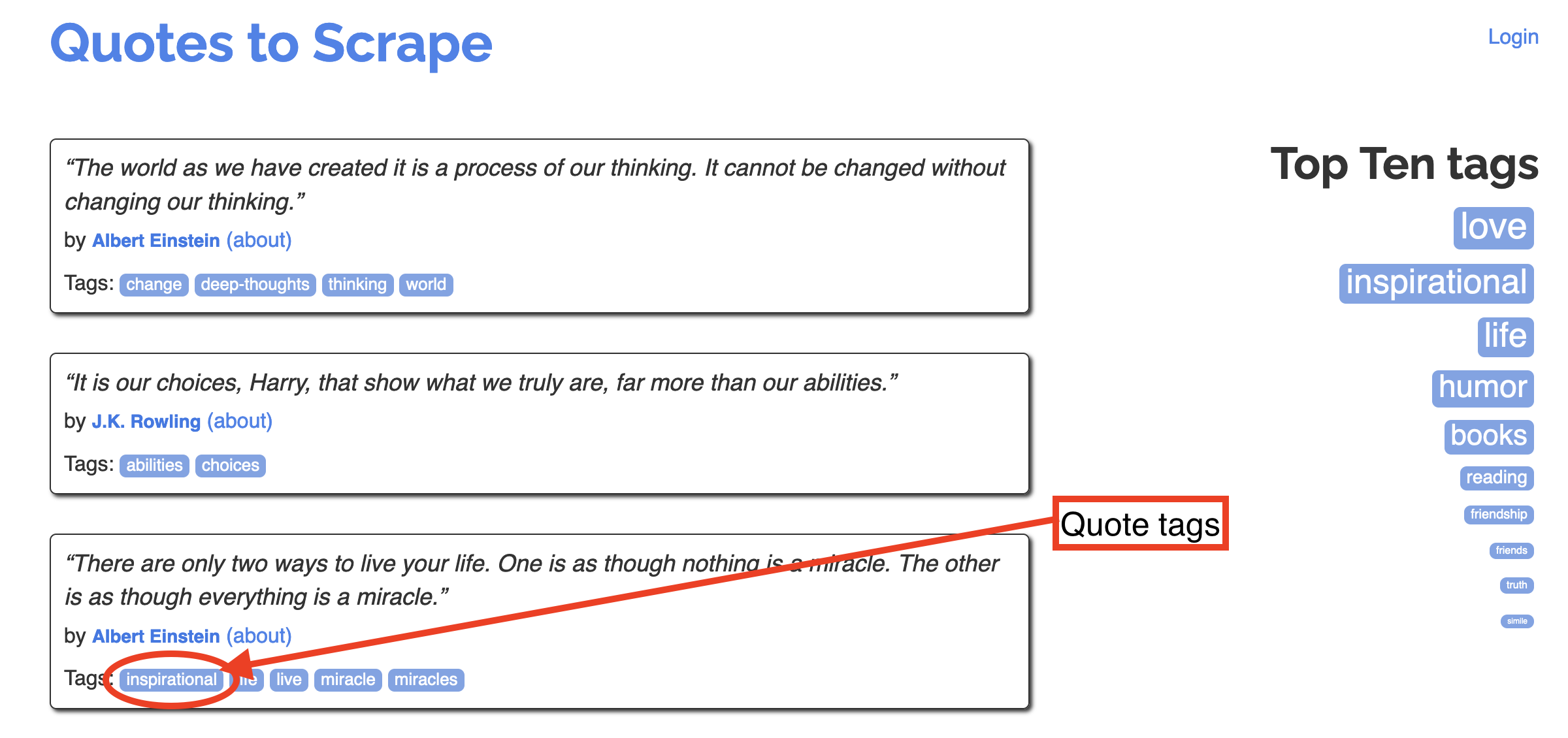
Lets inspect the tag ‘inspirational’ to figure out how we can scrape it.
<a class='tag' href='/tag/inspirational/page/1/'>inspirational</a>
Its an ‘a’ tag. This is a relative URL path. We can add the relative URL path to the quotes home page URL. Paste this into your browser “https://quotes.toscrape.com/tag/inspirational/page/1”. It displays all quotes with the inspirational tag. Notice that there is a next button at the bottom of the page, there’s multiple page containing inspirational quotes. We can reuse most of our previous code, all we really need to change is the URL.
pages = []
for i in range(1,2):
page = "https://quotes.toscrape.com" + '/tag/inspirational/page/' + str(i) + '/' # create a string of the url, with each loop the page number increases by one
pages.append(page) # write each url to a string
inspirational_soup = []
for i in range(0,len(pages)):
quotes_url = pages[i]
html_text = requests.get(quotes_url).text
quotes_soup = BeautifulSoup(html_text, 'html.parser')
inspirational_soup = quotes_soup.find_all('span', class_='text')
inspirational_quotes = []
for i in range(1,len(inspirational_soup)):
inspirational_quotes.append(inspirational_soup[i].text)
print(inspirational_quotes)
We have scrapped all the quotes with the tag ‘inspirational’.
Tag Scraping challenge
Change the tag to find different quotes
changing only the tag, try some of the other possible tags to scrape.
Part II
Lets look at another website that we can use to practice webscraping books.toscrape.com
our first challenge is to see if we can change the URL in the exisitng code for the new page we will scrape.
your activity here is to find and copy the code required
update URL solution
Supply the URL that you would like to scrape
quotes_url = 'https://bookstoscrape.com/'
Pull (download) all html data from the URL supplied above
html_text = requests.get(books_url).text
Parse the pull html data - make it look pretty
book_soup = BeautifulSoup(html_text, 'html.parser')'
- notice how need to change more than just the URL we will cover this more thoroughly as we go.
Challenge
Lets try to scrape all the prices of books. Inspect the price of a book and try to figure out what tag and attribute we can use to scrape it.
Solution
```html
£51.77
``` We can use the p tag and class attribute in the find_all function ```python find_all('p', class_="price_color") ```Lets build some code that scrapes price from the first 20 pages. First we need to figure out how to move onto the next page. Inspect the next page button.
<a href="catalogue/page-2.html">next</a>
Paste ‘https://books.toscrape.com/catalogue/page-2.html’ into your browser. Nice, it moves onto the next page.
pages = []
for i in range(0,20):
page = "https://books.toscrape.com" + '/catalogue/page-' + str(i) + '.html' # create a string of the url, with each loop the page number increases by one
pages.append(page) # write each url to a string
#check that the first and last URL's look correct.
print(pages[0], pages[-1]) # remember, [-1] indexes to the last from the end
price_soup = []
for i in range(0,len(pages)):
price_url = pages[i]
html_text = requests.get(price_url).text
soup = BeautifulSoup(html_text, 'html.parser')
price = soup.find_all('p', class_='price_color')
price_soup = price_soup + price
print(price_soup)
prices = []
for i in range(1,len(price_soup)):
prices.append(price_soup[i].text)
print(prices)
This returns a list of values
['£53.74', '£50.10', '£47.82', '£54.23'........]
The returned values look like strings, lets check.
type(prices[0])
str
Lets change the values to numbers, that is a better representation of price. We will change the string values to integers (whole numbers). This requires that we remove any characters, then round to a whole number.
for i in range(0,len(prices)):
prices[i] = prices[i].replace('£', '') # replace is a pandas function, here we replace £ with nothing
prices[i] = prices[i].replace('Â', '')
prices[i] = float(prices[i]) # change from character to float number
prices[i] = math.floor(prices[i]) # round prices down to whole integer number
print(prices)
Sometimes we might need to interact with the webpage. This could be to click the next button, or we might want to search for a particular item. In these cases we need to programatically interact with the webpage, this is where selenium comes in handy.
Selenium
Selenium is used to ineract with dynamic webpages. To use selenium you will need a webdriver. You can get a webdriver for chrome, although it can be difficult to use. I would suggest using the firefox webdriver If you need to use the Chrome webdriver, make sure it is the same version as chrome. Here is setup and download instructions.
Lets import selenium and webdriver to run the webpage in. We will also need to set up a webbrowser for selenium to run in.
import selenium
from selenium import webdriver
driver = webdriver.Firefox()
A new firefox window will open when we run the above. This window is used to interact with the webpage.
quotes_url = 'https://quotes.toscrape.com/'
driver.get(quotes_url)
Now lets use some xpath to click the next button to more onto the next page
driver.find_element_by_xpath('//span[text()="→"]').click()
We’ve used selenium to click the next page button.
Lets pull the quotes from the first page. We will do this the selenium way.
import selenium
from selenium import webdriver
driver = webdriver.Firefox()
quotes_url = 'https://quotes.toscrape.com/'
driver.get(quotes_url)
quotes = driver.find_elements_by_class_name('text')
for quotes_text in quotes:
print(quotes_text.text)
Now we can get the quotes from every page using selenium.
driver = webdriver.Firefox()
quotes_url = 'https://quotes.toscrape.com/'
driver.get(quotes_url)
quotes = []
for i in range(1,20):
q1 = driver.find_elements_by_class_name('text')
quotes.append(q1)
driver.find_element_by_xpath('//span[text()="→"]').click()
for quotes_text in quotes:
print(quotes_text.text)