Understanding webpage structure for webscraping
Introduction to webpage structure and how we use it to programatically scrape its contents.
Have you ever though about how the web actually works?
It consists of 2 very important parts, your web browser (i.e. FireFox, Chrome, or if your game Edge) and remote servers (servers are essentially external hard drives, although they can fill up entire warehouses).
When you interact with the web you send and recieve requests between your web browser and a remote server.
For example, you open FireFox and type “www.facebook.com” into the web address. Your actually sending a request to the facebook server, the facebook server then looks you up in its database and sends content back to your web browser for it to display. Then you click on the marketplace icon, this sends a request back to the facebook server, which looks at all the personal information it has about you and looks at you previous marketplace search history so that it can create a list of all ads you may like, it then sends this content back to your web browser for it to display to you.
That’s the internet….
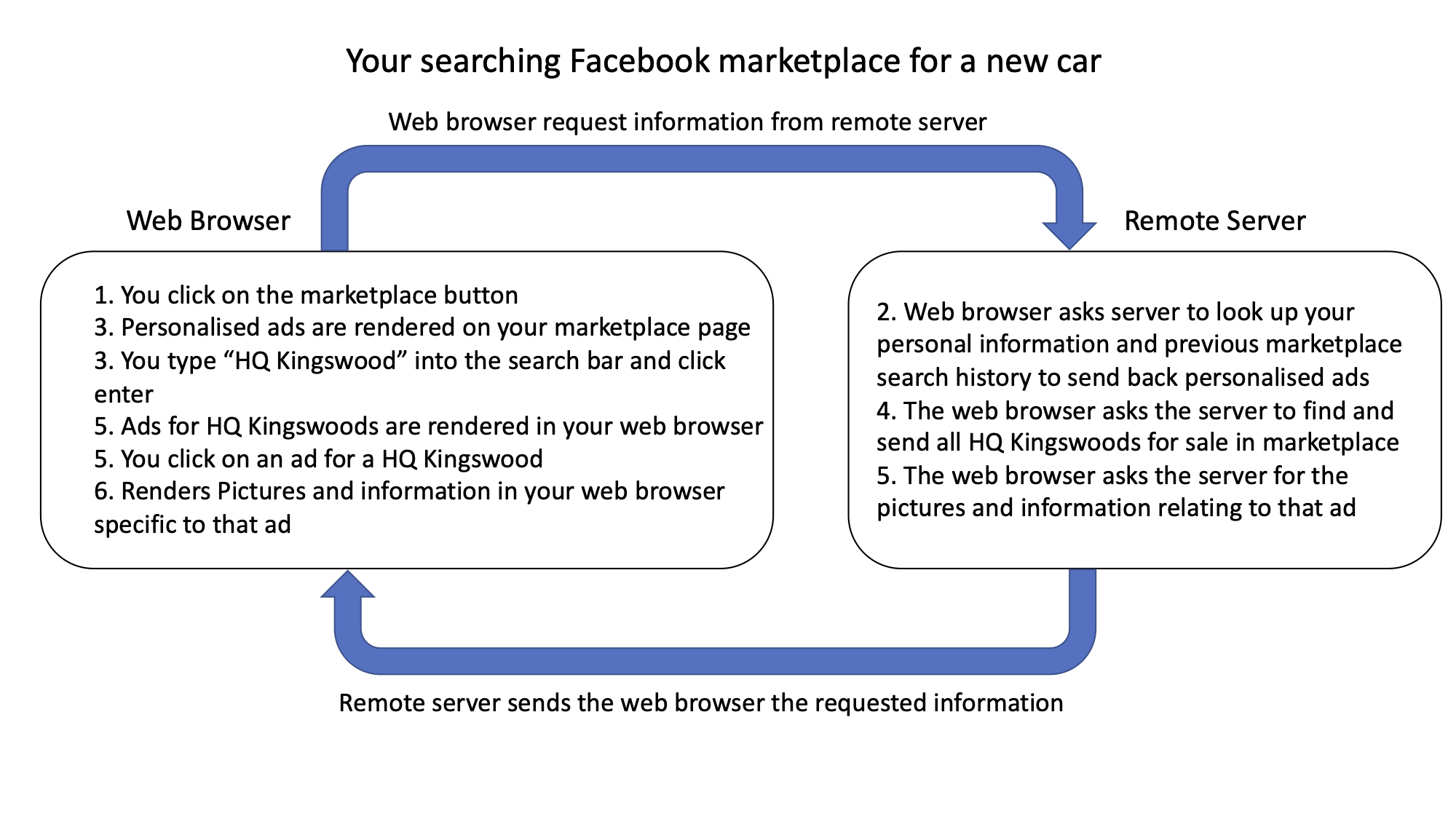
Dynamic content
You can only scrape the content that is loaded onto the page at the exact point in time when your code is executed. This is where static and dynamic web content play in. In the previous example, you cannot see any marketplace ads until Facebook’s server has sent the ads to your browser and the browser has displayed them. This is a very good example of dymanic content.
There is more subtle dynamic content that you might think is loaded onto the page you are scraping, but in fact is not.
- Some more subtle examples are a users location on a web map, its constantly changing as the user moves.
- The price of bitcoin on an exchange that provides real time updates.
- Ads in the sidebar of a website, they are constantly changing.
How do I know what is loaded into the browser and what is still sitting in the remote server?
Inspecting webpage structure
Open up a firefox or chrome web browser. Highlight a section and right click, a menu bar will appear, click on inspect. This will open a new tab showing the webpage structure, the relevant section will be highlighted.
Open the webpage quotes to scrape. And inspect the title.
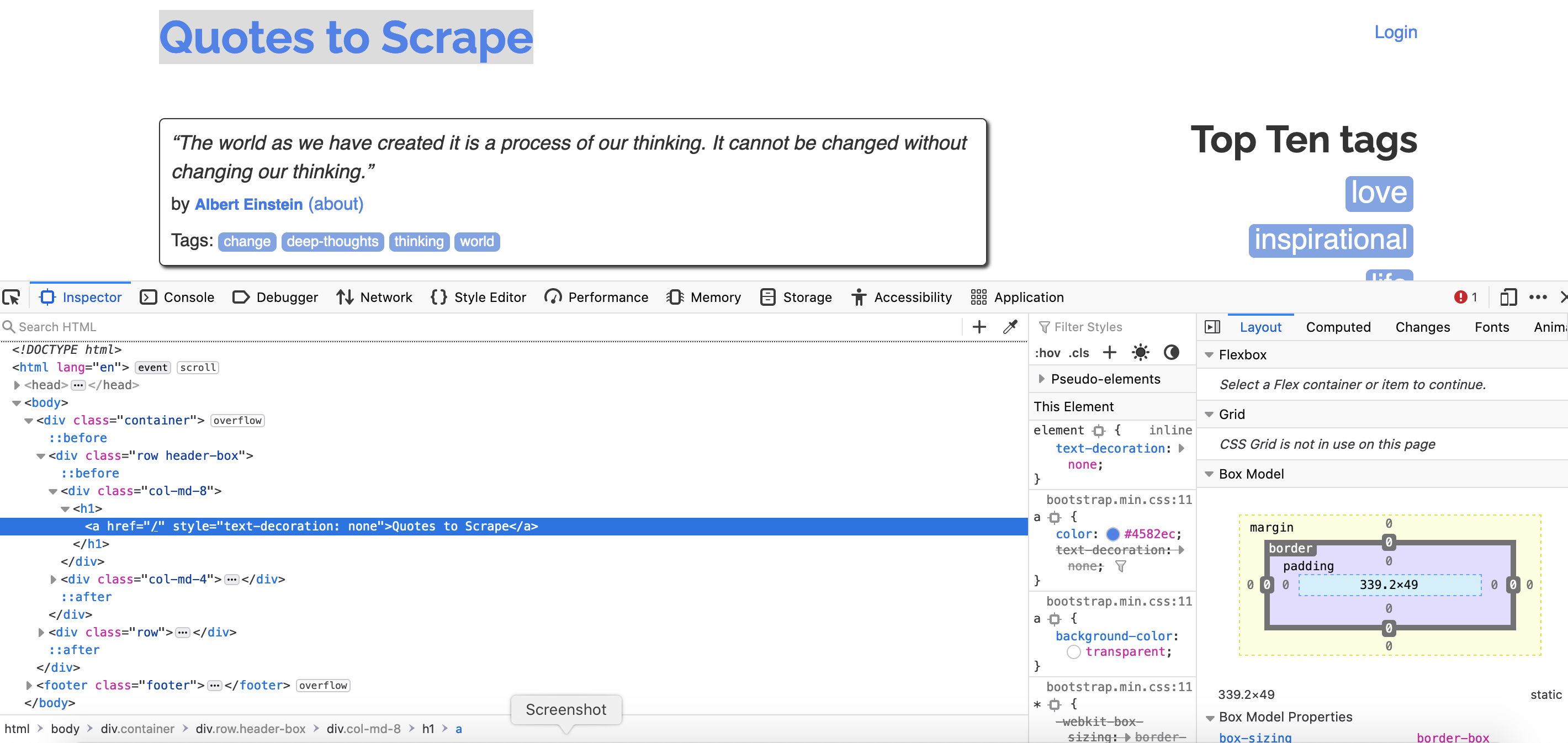
The following snippet of code contains the title information.
<h1>
<a href="/" style="text-decoration: none">Quotes to Scrape</a>
</h1>
First notice that its wrapper in a h1 tag. This represents the level 1 heading, or largest heading.
This tag contains everything between the beginning tag <h1> and ending tag </h1>.
It contains a style tag, references a css style “text-decoration: none”, and a hyperlink tag <a></a>. The a tag contains a href with a URL link, in this case “/”, which is shorthand for the homepage. Finally there is the raw text “Quotes to scrape”.
All of these different elements can be scraped.
The major webpage tags and elements, what they do and how they can be used to scrape information
When programatically scraping a webpage, you need a unique way to telling the program what information you are after.
Tags are html elements used to define the structure of a webpage.
** <head></head> this is where css and javascript is placed, can also reference script stored in another loction
** <body></body> This is the content that we see on the webpage
** <h1></h1> thru to <h6></h6> are headings
** <a></a> defines a hyperlink. Usually a URL to a different webpage
** <p></p> indicates a paragraph
** <div></div> is a division, think of it as an individual section of content
** <table></table> defines a table, and <tr></tr> defines table rows
Attributes can be added within tags, and again are useful for scraping specific information. For example, the following a tag contains a href attribute, and it contains the text “The XYZ website”. Both can be used for scraping.
<a href="www.xyz.com.au">The XYZ website</a>
The following <h2> tag can be scraped using the ‘style=”color:green”’, the ‘id=”py_scrape”’ and with the text ‘Scraping with python”
<h2 style="color:green" id="py_scrape">Scraping with python</h2>
The following code will generate a very simple webpage. Copy it, save it as webpage.html, then open is with your webbrowser.
<!DOC HTML>
<head>
<style>
.button {
border: none;
color: white;
padding: 15px 32px;
text-align: center;
text-decoration: none;
display: inline-block;
font-size: 16px;
margin: 4px 2px;
cursor: pointer;
}
.button1 {background-color: #4CAF50;} /* Green */
</style>
</head>
<body>
<h1 style="color:blue";>Simple webpage</h1>
<div id="buttons">
<button class="button button1">
<a href="https://quotes.toscrape.com/" target="_blank">Quotes to Quote</a>
</button>
</div>
<h2>secondary title<h2>
<div id="Lorem ipsum">
Lorem ipsum dolor sit amet, causae placerat consequat cu vis, id consequat interesset intellegebat eos.
Vix in falli abhorreant assueverit, solet everti aliquid id quo.
Mel consetetur intellegebat at, sumo veniam diceret vis et, eam id quaeque feugiat.
Ut cum ferri menandri, noluisse indoctum qui ei.
</div>
<h2 id="t3">Third title</h2>
<div>
<p>
Vix ei choro latine evertitur, quo iuvaret assueverit dissentias no.
Has te nullam nemore, paulo nullam in usu, vel apeirian corrumpit cu.
Ne natum mazim soluta per, ad mel vitae.
</p>
<p>
Menandri delicata cu eos, essent graecis vivendo pro te. Eu ius quot integre erroribus.
Mei ex postea epicurei adolescens, at rebum dolore vivendo nam.
Graecis adipisci sapientem cum ne, ad facilis tibique percipit vim, blandit dissentias duo ne.
</p>
</div>
</body>
Challenge
Using the above code. What tags/attributes can we use to scrape all the text from the paragraph that starts with:
Lorem ipsum dolor sit amet, causae placerat consequat cu vis
Try to find something unique, so that you don’t end up with information that you don’t want
Solution
```
Solution
```id="t3"``` If we use only the h2 tag we will scrape both h2 titles: secondary title Third title
Solution
We can use the h1 tag as its the only one on the page. ```