API's
Many websites offer API’s for retrieving their content. If a website has an API, use it.
What is an API? (Application Programming Interface)
API is the acronym for Application Programming Interface, which is a software tool that allows two applications to talk to each other. In the case of webscraping, an API allows a web browser (i.e. FireFox or chrome) or programming language (i.e. python, R, javascript) to talk to a database that stores the data on a webpage or collected by a webpage. The API allows you to read, display or “download” that data.
If a website has an API, then use it. Generally, it won’t let you collect data that your not allowed to collect, and its by far the easiest way to collect a websites data.
Check here for (by no means comprehensive) lists of websites with API access. You can use some of these to practice with.
Guardian.co.uk API
Australian news sources API
How do we use an API
You use URL’s to collect a websites data with an API, this is refered to as an API request. There are certain sections of the API request that can be manipulated to collect specific data. You will need to check out the websites API documentation for details.
Once you have a formulated a suitable API request, you will need to GET the data (i.e. download it onto your computer). This is most commonly achieved using a programming language, although you can paste the API request into your webbrowser and save the output. We generally use R or Python. If you are comfortable with either of these languages check these guides.
Some commonly used websites, such as Twitter, have packages that can be used to interact with the API. Packages that use Twitter API’s:
R: rtweet
python: Tweepy
Building an API request
First we need to formulate an API request. This can consist of the following:
- endpoint Think of an endpoint as the base URL for a website
- relative path for the dataset of interest
- an id if we’re after a specific case/species/type
- access token access tokens may be required
Access token - Authentication
Many websites require an access token for you to GET their data with an API. These are usually free, you just need to sign up. Once you have an access token you will need to put it into you API request. For example you will need to setup a twitter academic account to use their API.
Lets try it ourselves with a real example
NatureServe is a biodiversity conservation group that classifies, maps and sets biodiversity conservation goals. They have a huge range of biodiversity data for the Americas. There are a few pieces of information we need to create a get URL. This tutorial has been developed using the Mozilla Firefox browser, for ease of use we suggest you use this browser for coding and development. Download firefox here
We will GET information about the American black bear Ursus americanus.
All this information can be found in the websites API documentation
NatureServe API endpoint:
- endpoint https://explorer.natureserve.org/
Relative path to get data for species data:
- relative path /api/data/taxon/{ouSeqUid} note that {ouSeqUid} indicates the species of interest
The id for a specific species:
The API documentation provides an example API request for the relative path/id “/api/data/taxon/ELEMENT_GLOBAL.2.154701”. From this we know that the API requires a species id that looks like “ELEMENT_GLOBAL.2.154701”. Lets search for the American black bear on the NatureServe website and see if we can find an id.
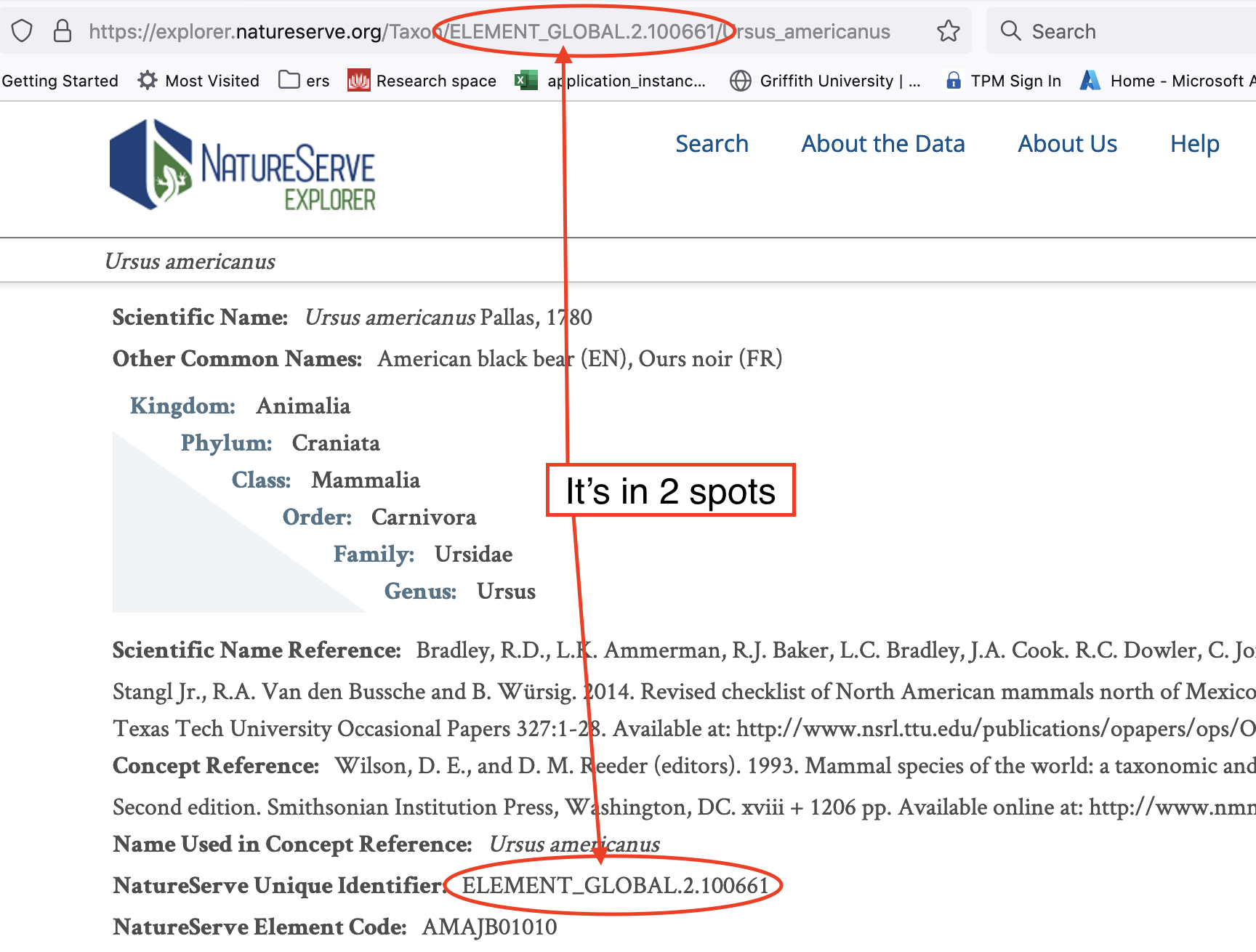
- an id ELEMENT_GLOBAL.2.100661
Put it all together and paste it into your webbrowser to display the data.
- API request https://explorer.natureserve.org/api/data/taxon/ELEMENT_GLOBAL.2.100661
First thing to do is test that your API request works, and that it GETs the correct data. To do this, paste the API request into your firefox browser, it should display the data nicely. If you only want a couple of requests then you can save the data using the save button to download it.
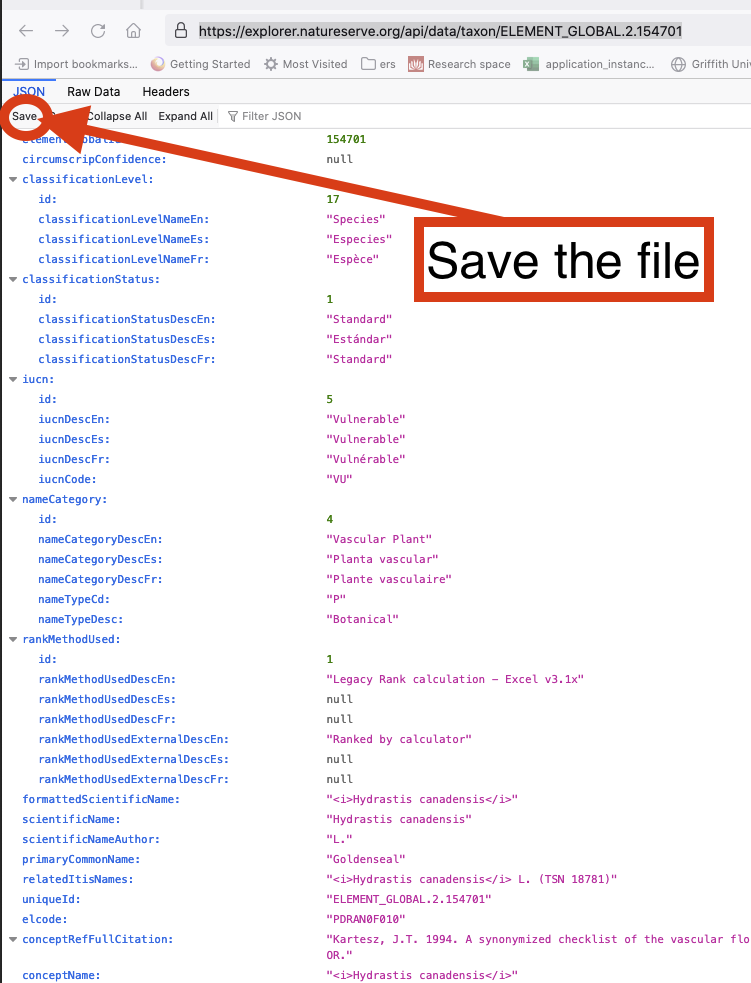
If you downloaded this data, it saved as a json file (most common type, but can be XML or HTML). The API documentation will tell you what the data will be. If you want to read json data into python you will need to follow the below code. You can install the json viewer extension so that it is displayed nicely.
import json
import os
os.chdir('/Users/Downloads/') # You will need to change the directory to the one on your computer
with open('american_black_bear.json') as dat:
data = json.load(dat)
If you have multiple API requests, or want to regularly collect the data, i.e. real-time updates, then you should use a programing language to GET the data.
This is JSON formatted data, you can also GET data from most API’s in XML and HTML format. You will most likely need to use a programming language to GET the data from the websites database onto your computer (or any other location you want to store/analyse the data).
Pull the data into python
import requests
import os
import json
api_request = 'https://explorer.natureserve.org/api/data/taxon/ELEMENT_GLOBAL.2.100661'
result = requests.get(api_request).json()
# Write the data to a json formatted text file on your computer
os.chdir('/Users/Documents/')
with open('American_black_bear.txt', 'w') as convert_file:
convert_file.write(json.dumps(result))
Pull the data into R
require(httr)
require(rjson)
api_request <- 'https://explorer.natureserve.org/api/data/taxon/ELEMENT_GLOBAL.2.100661'
get_request <- httr::GET(api_request)
results <- httr::content(get_request, as='text')
results_parsed <- fromJSON(results)
Another Example with covid data
Lets have a look at another API that provides global covid-19 statistics: https://api.covid19api.com/ Lets look at the documentation
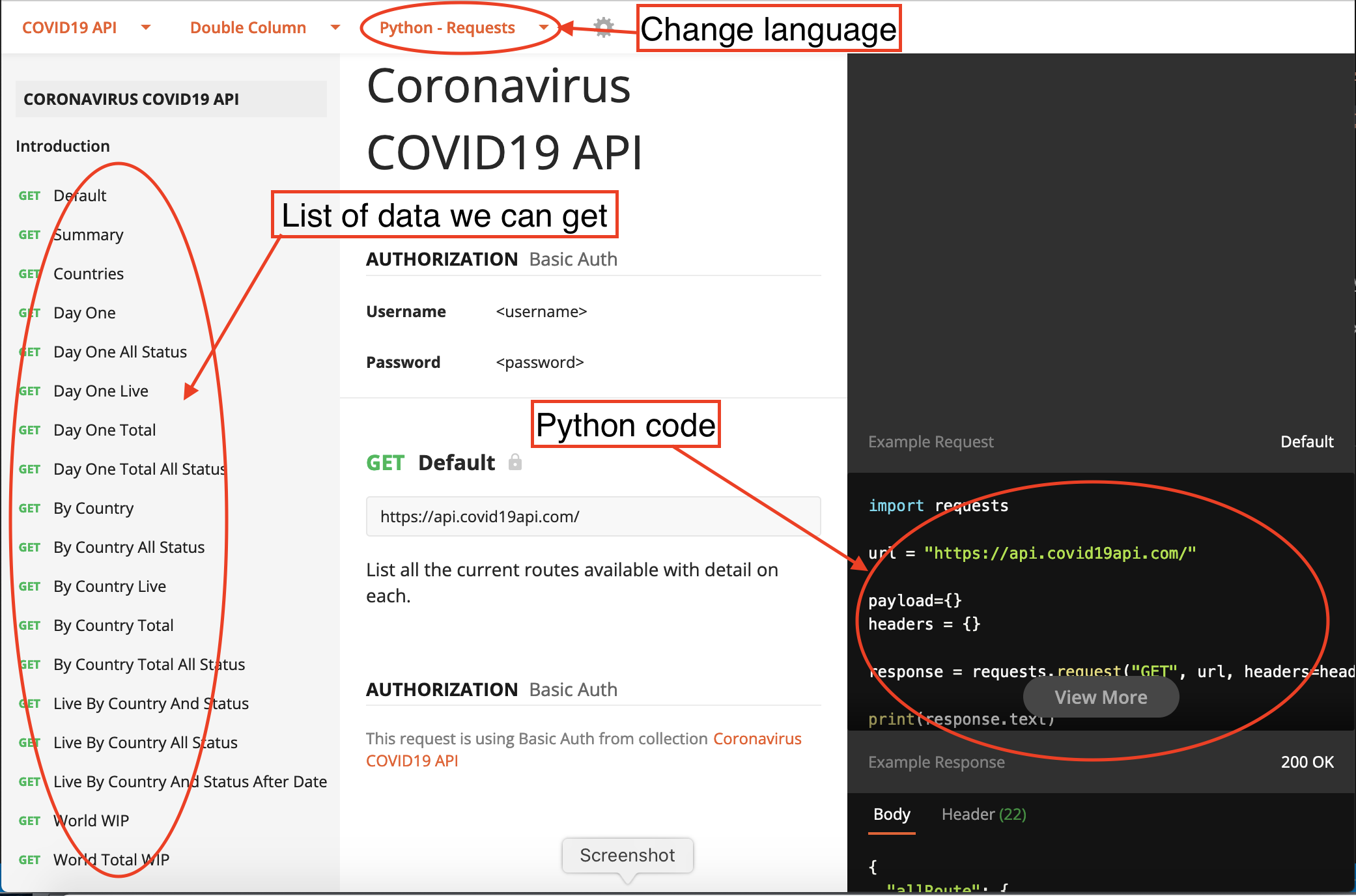
Select python as the language and requests as the package, it will provide you the code. Unfortunately it doesn’t show the code for R.
The left column contains all the different datasets we can get with API requests. Click on the default tab then “view more” button to look at some examples of the relative paths for data we can get from this API.
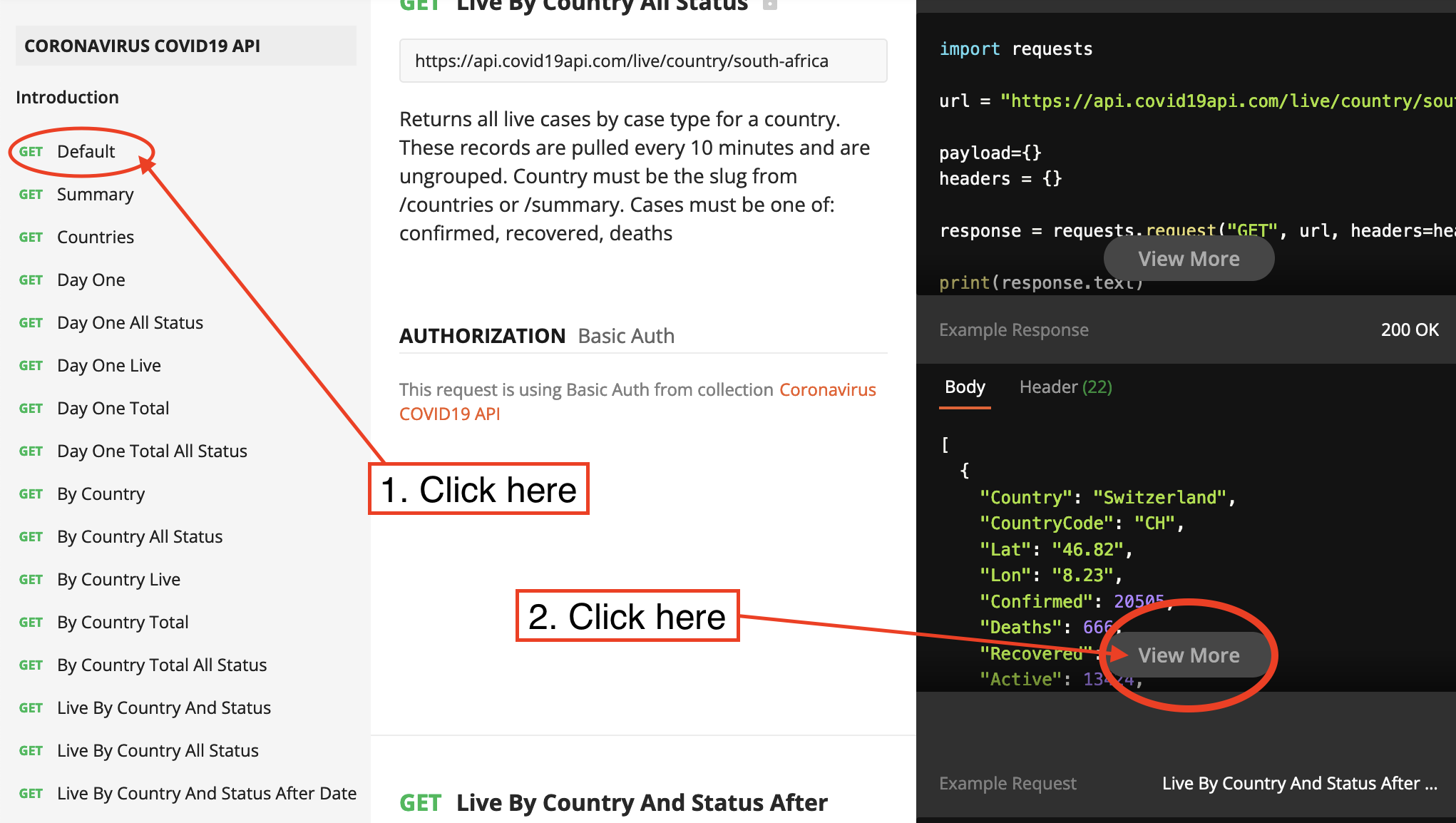

This is the relative path from the example above: /dayone/country/:country/status/:status/live This API request requires 2 id’s, :country is the id for the target country and :status is the id for the target status.
Lets use this relative path to get the infection data for Canada from the date of first confirmed case.
We can get a list of countries by adding country to the base URL, i.e. https://api.covid19api.com/countries. Paste the full URL “https://api.covid19api.com/countries” into you web-browser, ideally firefox (it will be far easier to read).
Use the find function click “crtl F” in the browser and a search bar will pop up, search Canada.
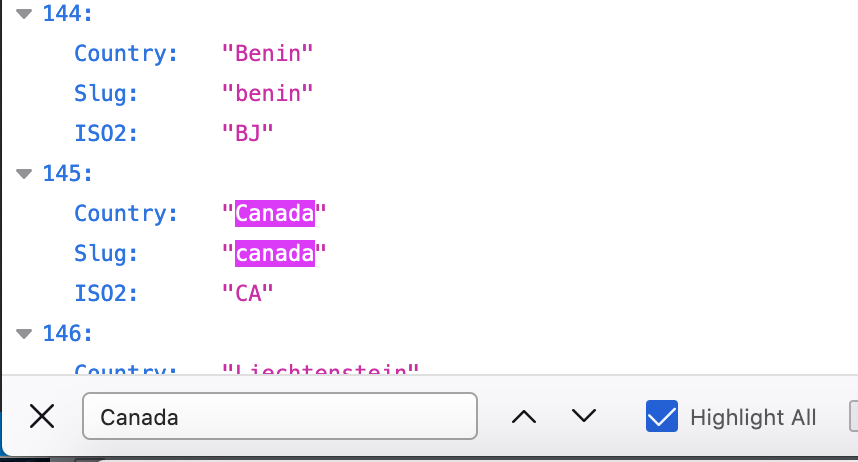
Our API request.
- endpoint: https://api.covid19api.com
- relative path: /dayone/country/:country/status/:status/live
- country id: canada
- status id: confirmed
https://api.covid19api.com/dayone/country/canada/status/confirmed/live
import requests
import os
import json
api_request = 'https://api.covid19api.com/dayone/country/canada/status/confirmed/live'
result = requests.get(api_request).json()
# Write the data to a json formatted text file on your computer
os.chdir('/Users/Documents/')
with open('canada_covid_daily.txt', 'w') as convert_file:
convert_file.write(json.dumps(result))